In the fast-evolving world of AI and machine learning, selecting the right GPU can make or break your project’s performance. NVIDIA’s H200 GPU and H100 GPU stand out as top choices for data centers and cloud environments. Both deliver exceptional compute power, but they target slightly different needs. This post compares the H200 GPU and
In the fast-evolving world of AI and machine learning, selecting the right GPU can make or break your project’s performance. NVIDIA’s H200 GPU and H100 GPU stand out as top choices for data centers and cloud environments. Both deliver exceptional compute power, but they target slightly different needs. This post compares the H200 GPU and H100 GPU head-to-head, focusing on specs, use cases, and cloud integration—key factors for developers, data scientists, and IT teams optimizing workloads.
Core Specifications: Where H100 GPU Sets the Foundation
The H100 GPU, launched as part of NVIDIA’s Hopper architecture, redefined AI acceleration. Built on TSMC’s 4nm process, it packs 80 billion transistors into a dual-socket design. Its standout feature is the Transformer Engine, which speeds up large language model (LLM) training and inference by handling mixed-precision computing efficiently.
Key specs include:
- Memory: 80GB HBM3 at 3.35 TB/s bandwidth.
- CUDA Cores: 16,896 FP32 Tensor Cores.
- Performance: Up to 4 petaFLOPS in FP8 precision for AI tasks.
- Power Draw: 700W TDP, scalable in multi-GPU setups.
In benchmarks, the H100 GPU excels in training models like GPT-3 equivalents, cutting time from weeks to days. For cloud users, it’s ideal for general-purpose AI workloads, from natural language processing to computer vision. Providers like Cyfuture Cloud offer H100 GPU instances for seamless scaling, supporting frameworks like TensorFlow and PyTorch out of the box.
H200 GPU: Enhanced Memory for Next-Gen Demands
Building directly on the H100 GPU‘s architecture, the H200 GPU introduces critical upgrades for memory-intensive applications. NVIDIA optimized it for the biggest AI models, like those exceeding 1 trillion parameters. The H200 GPU retains the Hopper core but swaps in HBM3e memory, boosting capacity and speed without redesigning the compute engine.
Notable advancements:
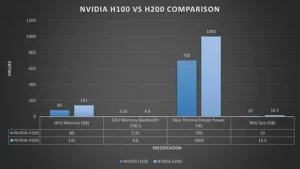
- Memory: 141GB HBM3e at 4.8 TB/s bandwidth—a 1.9x leap over H100 GPU.
- CUDA Cores: Same 16,896 as H100 GPU, ensuring compatibility.
- Performance: Up to 30% faster inference on LLMs; 1.4x memory bandwidth advantage.
- Power Draw: Matches H100 GPU at 700W, maintaining efficiency.
Real-world tests show the H200 GPU handling Llama 2 70B inference 1.9x faster than H100 GPU, thanks to reduced data movement bottlenecks. For cloud deployments, this means fewer GPUs needed per job, lowering costs. In GPU as a service models, the H200 GPU shines for generative AI, drug discovery, and climate simulations where datasets balloon quickly.
Head-to-Head Comparison: H200 GPU vs H100 GPU
| Feature | H100 GPU | H200 GPU | Winner for… |
| Memory Capacity | 80GB HBM3 | 141GB HBM3e | H200 (Large Models) |
| Memory Bandwidth | 3.35 TB/s | 4.8 TB/s | H200 (Inference Speed) |
| FP8 Performance | 4 petaFLOPS | Similar, optimized | Tie (Training) |
| Price per Instance | Lower entry point | Premium for capacity | H100 (Budget) |
| Power Efficiency | Excellent | Superior per byte | H200 (Scale) |
The H100 GPU wins for cost-sensitive projects or when 80GB suffices—think startup prototyping or standard ML pipelines. Switch to H200 GPU if your workloads hit memory walls, like fine-tuning massive multimodal models. Both support NVLink for multi-node scaling, but H200 GPU’s extra headroom future-proofs against growing model sizes.
Use Cases in Cloud and GPU as a Service
For AI developers renting GPUs, the choice hinges on workload. Use H100 GPU clusters for broad training tasks; its ecosystem is mature, with optimized containers on platforms like Kubernetes. Cyfuture AI’s H100 GPU offerings integrate with autoscaling, perfect for bursty inference.
The H200 GPU targets enterprise-scale AI. In cloud hosting, it powers recommendation engines at e-commerce giants or real-time analytics in finance. One example: A healthcare firm using H200 GPU reduced genomic sequencing time by 40% compared to H100 GPU setups, enabling faster drug candidate identification.
Both GPUs benefit from NVIDIA’s CUDA 12 ecosystem, including Magnum IO for low-latency networking. In GPU as a service, monitor metrics like GPU utilization via tools like DCGM to optimize costs—H200 GPU often yields better ROI for memory-bound jobs.
Challenges and Considerations
No GPU is perfect. H100 GPU supply chains have stabilized, but H200 GPU availability lags slightly due to HBM3e demand. Cooling remains critical; liquid-cooled racks are recommended for dense deployments to hit peak performance. Energy costs add up—plan for sustainable data centers.
Security-wise, both feature Confidential Computing via NVIDIA H100 Tensor Core GPUs’ trusted execution environments, safeguarding sensitive AI data in the cloud.
Future Outlook for H200 GPU and H100 GPU
As AI models grow, the H200 GPU positions itself as the go-to for 2026 workloads, bridging to Blackwell successors. Pair it with NVIDIA DGX systems for on-prem or cloud hybrids. For teams at Cyfuture Cloud, starting with H100 GPU eases migration while eyeing H200 GPU upgrades. As enterprises increasingly adopt generative AI, digital twins, and real-time analytics, the demand for higher memory capacity and faster throughput will continue to rise, further strengthening H200’s relevance.
At the same time, the H100 GPU will remain a dependable choice for balanced workloads, offering strong performance across training and inference tasks without excessive infrastructure costs. Its mature ecosystem ensures continued support, optimization, and wide availability in cloud platforms.
In summary, choose H100 GPU for versatile power; opt for H200 GPU when memory rules. Both drive AI innovation—test them in your cloud provider’s sandbox to match your needs while planning for future scalability and evolving AI demands.