
Curiosity-Driven Exploration in Reinforcement Learning: Solving the Sparse Reward Problem Reinforcement Learning (RL) has made significant strides in various applications, from robotics to gaming and dialogue systems. However, one of the fundamental challenges in RL is the sparse reward problem. In certain environments, an agent may not receive rewards for every action it takes, making
Curiosity-Driven Exploration in Reinforcement Learning: Solving the Sparse Reward Problem
Reinforcement Learning (RL) has made significant strides in various applications, from robotics to gaming and dialogue systems. However, one of the fundamental challenges in RL is the sparse reward problem. In certain environments, an agent may not receive rewards for every action it takes, making it difficult for the agent to learn optimal behavior. This is akin to navigating a maze where rewards are only given at the end of the path, making it challenging for the agent to figure out the correct sequence of actions.
Imagine our virtual agent, Mario, attempting to complete a level in a game. If we only provide a reward after Mario completes the entire level, it becomes hard for him to figure out which actions led to success. This lack of feedback at each step leaves Mario uncertain about whether he is making progress or not. This scarcity of guiding rewards results in what we call “sparse reward.”
So, how can we tackle this issue of sparse reward and empower our agents to learn effectively in such environments? This is where the concept of curiosity-driven learning comes into play.
What is Curiosity-Driven Learning?
Curiosity-driven learning is a technique that generates a secondary reward for the agent in environments where extrinsic rewards are sparse. It provides an internal motivation for the agent to explore its environment and learn based on curiosity.
Image by: https://www.researchgate.net/figure/The-6-steps-of-curiosity-based-learning_fig4_234650995
In curiosity-driven learning, the reward is divided into two components:
Primary Rewards (Extrinsic Reward): These rewards are given to the agent upon completing an episode or reaching specific checkpoints. However, since rewards are sparse, the agent does not receive feedback for every action taken.
Curiosity Reward (Intrinsic Reward): This is the reward the agent receives for exploring new areas or states. The more different the next state is compared to the expected state, the higher the curiosity reward. This reward is provided for every action taken by the agent, encouraging it to explore and learn from novel experiences.
Calculating Curiosity Reward
To calculate curiosity reward, we use a forward prediction model. This model takes the current state (S) and the action taken (A) as input and predicts the next state (S’). The difference between the predicted next state and the actual next state obtained from the environment after applying action A becomes the curiosity reward. This forward prediction model is sometimes referred to as the “Neural Network” and uses an encoded version of the state generated by an Encoder model.
Addressing Challenges: Noisy TV and Trivial Randomness
However, there are challenges in implementing curiosity-driven learning:
Noisy TV Problem: The Neural Network used for calculating the curiosity reward may learn to produce random or noisy next_states, leading to larger prediction errors and maximizing intrinsic rewards. This can be compared to a Noisy TV where the screen is filled with random pixels. The model might end up generating meaningless output indefinitely.
Trivial Randomness: In complex environments like Mario, there may be multiple elements that have no impact on the agent’s progress (e.g., birds, clouds for aesthetic purposes). High prediction error on such trivial elements may distract the agent from focusing on crucial elements.

Image by: https://www.mdpi.com/1099-4300/23/12/1654
Introducing Inverse Dynamics
To overcome these challenges, we introduce two additional Neural Networks:
Inverse Dynamics Prediction Model: This model takes the current state (S) and the next state (S’) as input and predicts the action taken (A). We use an encoded version of these states to consider important information only.
Encoder Model: This model encodes the states into a lower-dimensional embedding, compressing trivial information.
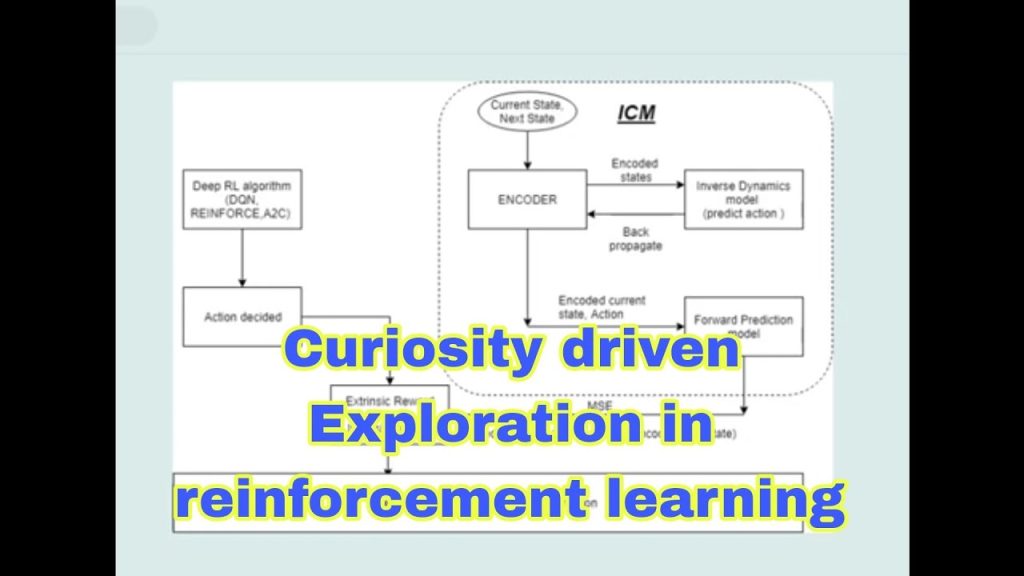
Integrating the Intrinsic Curiosity Module (ICM)
The Intrinsic Curiosity Module (ICM) consists of the Encoder model, Inverse Dynamics model, and Forward Prediction model. The Encoder generates embeddings for the current state and next state, which are then fed into both the Inverse Dynamics and Forward Prediction models. The Encoder is trained using the error from the Inverse Dynamics model, with no separate training for the Encoder.
ICM can be integrated with existing deep reinforcement learning algorithms, such as DQN, A2C, DDPG, or REINFORCE, to resolve the sparse reward problem. By integrating ICM, we empower agents like Mario to explore, learn, and navigate through environments with sparse rewards efficiently.
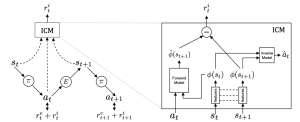
Image by: https://medium.com/swlh/curiosity-driven-learning-with-openai-and-keras-66f2c7f091fa
Conclusion
Curiosity-driven exploration is a promising approach to address the sparse reward problem in reinforcement learning environments. By providing intrinsic rewards based on curiosity, agents can learn from unguided experiences and improve their decision-making capabilities. Although challenges like noisy TV and trivial randomness exist, the integration of Intrinsic Curiosity Module (ICM) can mitigate these issues, leading to more efficient agent training.
As RL and curiosity-driven learning continue to evolve, we can expect more breakthroughs in agent intelligence and the ability to tackle increasingly complex tasks in various domains.













Leave a Comment
Your email address will not be published. Required fields are marked with *