

1. Introduction to ChatGPT Before we start the training process, we should comprehend the basis of ChatGPT. GPT-3 is based on a pre-trained model that was initially trained on a huge and varied collection of Internet data. This model’s language skills and knowledge were vast. However, it needed to be further tweaked for certain
1. Introduction to ChatGPT
Before we start the training process, we should comprehend the basis of ChatGPT. GPT-3 is based on a pre-trained model that was initially trained on a huge and varied collection of Internet data. This model’s language skills and knowledge were vast. However, it needed to be further tweaked for certain commitments and improved its dependability.
2. Pre-training of labeled data with GPT-3.
The fine-tuning began by collecting the human prompts that are frequently used for GPT from the OpenAI website. These requests were then introduced to human labelers and clients, who were asked to provide the appropriate responses for every request. By using the 12,725 labeled instances, the model underwent supervised learning to modify its parameters and enhance its functionality.
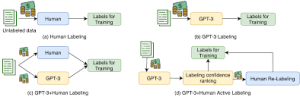
Image by: https://www.microsoft.com/en-us/research/uploads/prod/2021/09/emnlp2021.pdf
3. Ranker Model: Training the Reward System
In the subsequent step, OpenAI sourced human prompts and received multiple responses from the model for each prompt. Based on their quality and relevance, the human labelers were asked to rank these outputs. Training the Ranker model required the use of the data yielded. This model inputs the ranked results and outputs a score for each one, demonstrating how well or relevant they are. The process involves around 33,207 prompts and a significantly greater number of training samples, using a variety of ranked outputs.
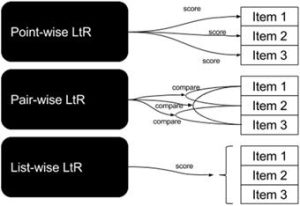
Image by: https://livebook.manning.com/book/practical-recommender-systems/chapter-13/v-16/
4. Fine-Tuning a Reinforcement Learning (PPO)
The fine-tuning procedure was followed through reinforcement learning and Proximal Policy Optimization algorithm (PPO) once the Ranker model was put in place. Human prompts were gathered anew, and the PPO model was iteratively fine-tuned using these prompts together with the rewards produced by the Ranker model. By using reinforcement learning, ChatGPT could enhance its responses based on the rewards it received, which led to more precise and appropriate textual communication. The PPO fine-tuning needed 31,144 prompts.
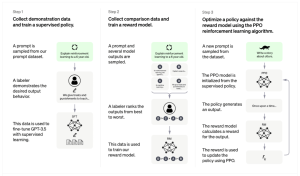
Image by: https://deepsense.ai/how-can-we-improve-language-models-using-reinforcement-learning-chatgpt-case-study/
5. The Model’s Sibling: InstructGPT
While developing ChatGPT, OpenAI also released a comparable model named InstructGPT, which is utilized in the training procedure. While ChatGPT and InstructGPT have different fine-tuning and reinforcement learning processes, their goals are similar: achieving advanced language generation capabilities. Both use a similar fine-tuning approach, but there may be subtle differences in the details.
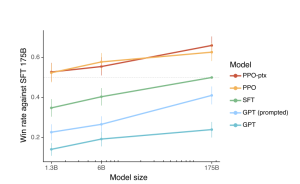
Image by: https://www.kaggle.com/discussions/general/373606
6. Conclusion: ChatGPT’s Training Process: A Comprehensive Exploration
ChatGPT’s growth from a pre-trained model to a fantastic conversational AI involved supervised and reinforcement learning strategic fine-tuning. ChatGPT leveraged a minuscule amount of data and a Ranker model centered on rewards to develop human-like and relevant replies. The training process demonstrates how AI technology can produce adaptable language models that can accomplish diverse tasks.
The training process of ChatGPT reveals the AI community’s dedication to excellence and discovering the possibilities of AI.




















Leave a Comment
Your email address will not be published. Required fields are marked with *